Spring Cache(@Cacheable) + Spring Data Redis 사용 시 record 직렬화 오류 원인과 해결
이 글은 Spring Data Redis에서 GenericJackson2JsonRedisSerializer를 사용할 때 발생할 수 있는 직렬화 문제를 다룹니다.
직렬화 방식에 따라 문제가 나타나지 않을 수도 있으므로, 다른 직렬화기를 사용하는 경우에는 영향을 받지 않을 수 있습니다.
최근 프로젝트에서 record와 Spring의 @Cacheable을 함께 사용하던 중, 예상치 못한 문제를 마주했습니다. 처음에는 단순한 캐시 설정 이슈로 보였지만, 원인을 추적하던 중 Spring Data Redis와 Jackson 간의 직렬화 처리 방식에서 흥미로운 구조적 문제가 있다는 걸 알게 되었습니다.
이 글에서는 @Cacheable을 사용해 데이터를 Redis에 캐싱할 때, record와 GenericJackson2JsonRedisSerializer 조합에서 어떤 문제가 발생하는지, 그 원인은 무엇인지, 그리고 어떻게 해결할 수 있는지를 공유합니다.
문제 상황
record 데이터 클래스를 정의하고, Spring의 @Cacheable을 사용해 Redis 캐싱을 적용했습니다. 아래는 문제가 발생했던 코드의 예시입니다.
public record UserRecord(Long id, String name) {}@Service
public class UserService {
@Cacheable(value = "users", key = "#id")
public UserRecord getUser(Long id) {
return new UserRecord(id, "User-" + id);
}
}Redis 캐시 설정은 아래와 같이 GenericJackson2JsonRedisSerializer와 커스터마이즈한 ObjectMapper를 사용하고 있었습니다.
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration cacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(TTL)
.serializeKeysWith(fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(fromSerializer(
new GenericJackson2JsonRedisSerializer(createRedisObjectMapper())
));
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(cacheConfiguration)
.build();
}
private ObjectMapper createRedisObjectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.findAndRegisterModules();
mapper.activateDefaultTyping(
mapper.getPolymorphicTypeValidator(),
ObjectMapper.DefaultTyping.NON_FINAL,
JsonTypeInfo.As.PROPERTY
);
return mapper;
}처음 요청은 정상 동작했지만, 두 번째 요청부터 아래와 같은 예외가 발생했습니다.
com.fasterxml.jackson.databind.exc.InvalidTypeIdException:
Could not resolve subtype of [simple type, class java.lang.Object]:
missing type id property '@class'원인 분석
@Cacheable 동작 과정
아래 그림은 @Cacheable의 내부 동작 흐름을 나타낸 것입니다.
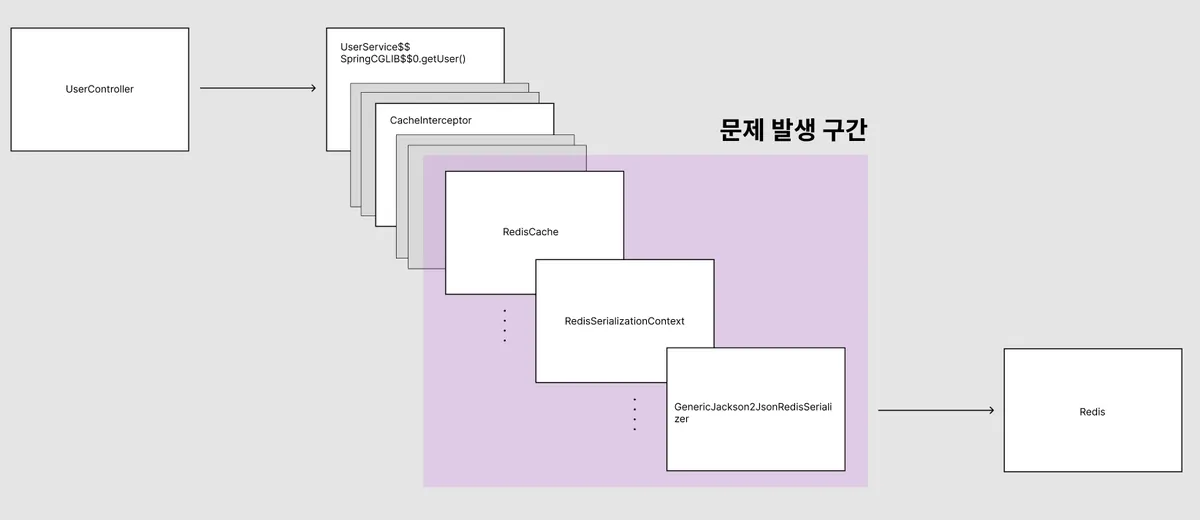
캐시 저장 시에는 GenericJackson2JsonRedisSerializer를 통해 객체를 JSON으로 직렬화하고, 캐시 조회 시에는 저장된 JSON을 다시 객체로 역직렬화합니다. 문제는 바로 이 역직렬화 과정에서 발생합니다.
이 직렬화기는 내부적으로 Jackson의 ObjectMapper를 이용해 데이터를 직렬화하고, 이후 다시 역직렬화하여 캐시된 데이터를 반환합니다. 그런데 문제는 이 ObjectMapper의 타입 정보 처리 방식에 있습니다.
mapper.activateDefaultTyping(
mapper.getPolymorphicTypeValidator(),
ObjectMapper.DefaultTyping.NON_FINAL,
JsonTypeInfo.As.PROPERTY
);위 설정은 final이 아닌 클래스만 타입 정보(@class)를 JSON에 포함해 타입을 직렬화합니다. 하지만 Java의 record는 자동으로 final로 선언되기 때문에 이 조건에서 해당하지 않습니다.
따라서 실제 저장 형태는 기대와 달라집니다.
[예상 JSON]
{
"@class": "com.example.springcachetest.domain.UserRecord",
"id": 1,
"name": "User-1"
}[실제 JSON]
{
"id": 1,
"name": "User-1"
}여기서 문제는 해당 데이터를 다시 읽을 때 발생합니다.
JSON 안에 타입 정보가 없으면 역직렬화 대상 클래스(Type)를 유추하지 못하고, 결국 다음과 같은 예외를 발생하게 됩니다.
InvalidTypeIdException: missing type id property '@class'문제를 복잡하게 만든 요소
이 문제가 더 까다로웠던 이유는 다음과 같습니다.
- 컴파일 타임엔 전혀 문제가 없음 (타입 정보는 런타임에 처리되기 때문에, 코드는 정상적으로 컴파일됩니다.)
- 첫 요청은 정상 처리 (캐시에 데이터가 없기 때문에, 원본 데이터를 그대로 반환하면서 문제가 드러나지 않습니다.)
- 두 번째 요청부터 역직렬화가 발생하면서 예외 발생 (캐시에 저장된 JSON을 Jackson이 역직렬화하려 할 때 타입 정보가 없어 예외가 발생합니다.)
- 테스트나 코드 리뷰 단계에서 포착하기 어려움 (캐시가 실제로 동작하는 상황을 테스트하거나 시뮬레이션하지 않으면 문제가 재현되지 않기 때문입니다.)
즉, 이 문제는 코드에 명백한 오류 없이 숨어 있다가 런타임에만 발생하는 유형이라, 사전에 발견하고 대응하기 어려운 리스크가 있는 문제였습니다.
Jackson의 설계 의도
왜 Jackson은 final class에 타입 정보를 안 붙일까?
처음 이 문제를 마주했을 때는, record인 경우 클래스 정보가 누락되어 역직렬화가 실패하는 현상을 보고 Jackson 측의 버그라고 판단해 이슈를 제보했습니다.
하지만 관련 문서를 찾아보고, 컨트리뷰터와 논의하면서 Jackson의 설계 철학을 이해할 수 있었습니다.
Jackson이 왜 final 클래스에 타입 정보를 포함하지 않는지 이해하기 위해, 다형성 처리가 필요한 상황을 예로 들어보겠습니다.
public class Zoo {
public Animal animal;
...
}
class Animal {
public String name;
protected Animal() { }
...
}
class Dog extends Animal {
public double barkVolume;
public Dog() { }
...
}
class Cat extends Animal {
boolean likesCream;
public int lives;
public Cat() { }
...
}(참고: Jackson 공식 문서 – Polymorphic Deserialization)
다형성을 지원하지 않는 경우
아래 코드는 다형성을 지원하지 않는 objectMapper의 직렬화 결과를 확인해보는 테스트 코드입니다.
@Test
@DisplayName("다형성을 지원하지 않는 ObjectMapper 테스트")
public void objectMapperTest1() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
Dog dog = new Dog("Choco", 12.3);
Zoo zoo = new Zoo(dog);
String json = objectMapper.writeValueAsString(zoo);
System.out.println(json); // 출력 결과: {"animal":{"name":"Choco","barkVolume":12.3}}
Zoo result = objectMapper.readValue(json, Zoo.class); // 실패
}실행 결과
출력 결과: {"animal":{"name":"Choco","barkVolume":12.3}}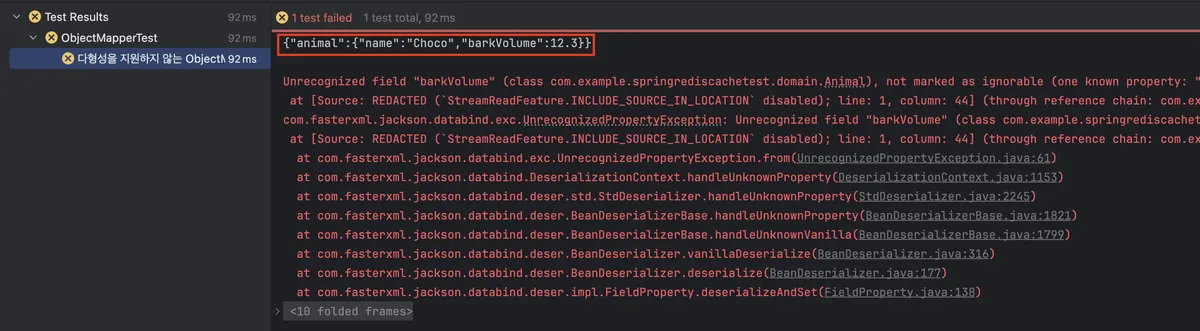
다형성을 지원하도록 설정한 경우
아래 코드는 다형성을 지원하도록 설정한 objectMapper의 직렬화 결과를 출력하는 테스트 코드입니다.
@Test
@DisplayName("다형성을 지원하는 ObjectMapper 테스트")
public void objectMapperTest2() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.activateDefaultTyping(
objectMapper.getPolymorphicTypeValidator(),
DefaultTyping.NON_FINAL,
JsonTypeInfo.As.PROPERTY
); // 다형성을 지원하기 위해 타입 정보를 포함하도록 설정
Dog dog = new Dog("Choco", 12.3);
Zoo zoo = new Zoo(dog);
String json = objectMapper.writeValueAsString(zoo);
System.out.println(json); // 출력 결과: {"@class":"com.example.domain.Zoo","animal":{"@class":"com.example.domain.Dog","name":"Choco","barkVolume":12.3}}
Zoo result = objectMapper.readValue(json, Zoo.class); // 성공
}실행 결과
출력 결과: {"@class":"com.example.domain.Zoo","animal":{"@class":"com.example.domain.Dog","name":"Choco","barkVolume":12.3}}![[polymorphic_test_success_case.png]](/images/wp/2690582fbc_.png.webp)
위 예제에서 볼 수 있듯, Jackson은 기본적으로 다형성을 자동 지원하지 않으며, 이를 위해선 타입 정보를 명시적으로 포함해야 합니다.
이를 위해 ObjectMapper.activateDefaultTyping(...) 설정이 사용됩니다.
하지만 record는 Java에서는 final이기 때문에, DefaultTyping.NON_FINAL 설정에 따라 타입 정보가 의도적으로 생략됩니다.
즉, 이 문제는 Jackson의 관점에서는 올바른 동작입니다.
record는 다형성을 전제로 하지 않으며, 타입 정보가 필요하지 않다는 가정하에 동작하는 것이므로, Jackson은 타입 정보를 붙이지 않습니다.
문제는 반대로, record에도 타입 정보가 있을 것으로 기대하는 Spring Data Redis 같은 라이브러리에서는 이 생략이 치명적인 이슈가 될 수 있다는 점입니다.
결국, Jackson의 설계 의도와 실제 라이브러리 사용 환경 간의 간극이 이 문제의 본질이었습니다.
기존 해결책과 한계
이 이슈는 jackson-databind의 공식 이슈에서도 논의된 바 있으며, 다음과 같은 해결 방법들이 제안되었습니다.
1. DefaultTyping.EVERYTHING 사용
mapper.activateDefaultTyping(
mapper.getPolymorphicTypeValidator(),
ObjectMapper.DefaultTyping.EVERYTHING,
JsonTypeInfo.As.PROPERTY
);모든 클래스에 타입 정보를 붙여 직렬화합니다.
record, final class 여부와 상관없이 타입 정보가 붙기 때문에 문제는 해결됩니다.
하지만 다음과 같은 단점이 존재합니다.
- 필요한 경우가 아닌 곳에도 타입 정보가 붙으면서, 직렬화 결과가 꽤 커질 수 있습니다.
- 성능 측면에서도 이점이 없고, 결정적으로 이 설정은 Jackson 측에서도 Deprecated 방향으로 가는 중입니다.
결론적으로 현재는 추천되지 않는 방법입니다.
2. record 대신 class 사용
가장 현실적인 해결책입니다.
public class UserRecord {
private Long id;
private String name;
// 생성자, getter 등 생략
}record 대신 일반 클래스를 사용하면 DefaultTyping.NON_FINAL 조건에 부합하게 되고,
Jackson이 타입 정보를 자동으로 붙여주기 때문에 문제는 발생하지 않습니다.
3. Wrapper 클래스 + @JsonTypeInfo 사용
그래도 꼭 record를 써야 한다면, 우회 방법이 있습니다. Record이든 다른 클래스이든 Wrapper 클래스 안에 넣고 @JsonTypeInfo를 붙여주는 방식입니다.
public class Wrapper {
@JsonTypeInfo(use = Id.CLASS, include = As.WRAPPER_ARRAY)
public Object cached;
}이렇게 하면 Default Typing 설정 없이도 Record든 무엇이든 타입 정보가 포함된다는 보장이 있습니다. 이는 다형성 처리의 base type을 java.lang.Object로 강제하기 때문이고, non-Final이기 때문입니다.
근본적 해결책 모색
앞서 살펴본 바와 같이, 이러한 이슈가 있을 때 jackson 측에서 제시한 해결 방식의 문제점은 다음과 같습니다.
-
record 대신 class 사용: 현재 팀 프로젝트에서는 record를 많이 사용하고 있기 때문에, 실수로 기본 class가 아닌 record에 캐싱을 적용하면 문제가 발생할 수 있습니다.
-
Wrapper 클래스 + @JsonTypeInfo 명시적으로 지정: Wrapper 클래스를 만들어 타입 정보를 보장할 수 있지만, 매번 Wrapper로 감싸야 하는 번거로움이 있고, Redis 설정 레벨에서 자동으로 처리하지 않으면 개발자가 일일이 신경 써야 합니다.
이런 방식들은 모두 GenericJackson2JsonRedisSerializer을 사용하는 입장에선 개발자의 실수 가능성을 전제로 하고 있기 때문에, 보다 근본적인 해결책이 필요하다고 판단했습니다.
그렇다면 GenericJackson2JsonRedisSerializer 내부 구현 또는 기본 설정을 변경하여, Spring Data Redis 차원에서 문제를 방지할 수 있는 구조적 해결책은 없을까요?
Spring Data Redis의 입장
이 과정에서 Spring Data Redis 이슈 #2601을 참고했는데,
여기서 Spring 측은 다음과 같은 입장을 명확히 하고 있습니다.
GenericJackson2JsonRedisSerializer에서 사용하는 ObjectMapper에 대해
기본 모듈 등록이나 커스텀 설정은 Spring이 아닌 사용자 책임이라는 방침을 유지하고 있다.
Spring Data Redis는 기본적인 모듈 등록이나 커스텀 설정을 제공하지 않으며,
이는 Jackson의 버전에 따라 직렬화 동작이 달라질 수 있는 점 때문입니다.
라이브러리 내부에서 Jackson의 모든 변경 사항을 추적해 대응하는 것은 오히려 불안정성과 유지보수 비용을 높인다고 판단한 것입니다.
따라서 Spring은 ObjectMapper의 다형성 처리나 직렬화 전략이 필요한 경우,
개발자가 명시적으로 커스터마이징하여 주입하는 방식을 권장합니다.
하지만 이런 Spring Data Redis의 철학에도 불구하고, 실무에서는 개발자 실수를 최소화할 수 있는 보다 구조적인 해결책이 필요합니다.
GenericJackson2JsonRedisSerializer 내부 로직 확인
Spring Data Redis 내부에서 직접 대응하기가 어렵다면, 개발자가 ObjectMapper를 커스터마이징할 때 실수를 줄일 수 있는 더 근본적인 접근이 가능한지 확인하기 위해 GenericJackson2JsonRedisSerializer 내부 구현을 직접 들여다보았습니다.
1. 직렬화 로직
@Override
public byte[] serialize(@Nullable Object value) throws SerializationException {
if (value == null) {
return SerializationUtils.EMPTY_ARRAY;
}
try {
return writer.write(mapper, value);
} catch (IOException ex) {
throw new SerializationException("Could not write JSON: %s".formatted(ex.getMessage()), ex);
}
}직렬화는 ObjectMapper.writeValueAsBytes()를 그대로 사용하는 구조이며,
타입 정보를 포함할지 여부는 전적으로 ObjectMapper 설정에 따릅니다.
2. 역직렬화 로직
@Override
@SuppressWarnings("unchecked")
public <T> T deserialize(@Nullable byte[] source, Class<T> type) throws SerializationException {
Assert.notNull(type, "Deserialization type must not be null; Please provide Object.class to make use of Jackson2 default typing.");
if (SerializationUtils.isEmpty(source)) {
return null;
}
try {
return (T) reader.read(mapper, source, resolveType(source, type));
} catch (Exception ex) {
throw new SerializationException("Could not read JSON: %s".formatted(ex.getMessage()), ex);
}
}역직렬화 과정에서는 ObjectMapper.readValue()를 호출하기 전에 resolveType()을 사용해 타입 정보를 추론합니다.
protected JavaType resolveType(byte[] source, Class<?> type) throws IOException {
if (!type.equals(Object.class) || !defaultTypingEnabled.get()) {
return typeResolver.constructType(type);
}
return typeResolver.resolveType(source, type);
}즉, 역직렬화는 JSON 문자열 내부에 타입 정보가 존재할 경우 해당 타입을 추론해 deserialize하게 됩니다.
문제의 핵심과 해결 방향
앞서 살펴본 Jackson의 다형성 처리와 달리, GenericJackson2JsonRedisSerializer는 특별한 방식으로 동작합니다. 일반적인 Jackson 사용과 달리 명시적인 클래스 타입을 전달받지 않고, JSON 내부에 포함된 타입 정보 만으로 타입을 추론해야 합니다.
이는 캐시에서 객체를 꺼낼 때 원본 타입 정보가 없기 때문입니다. 따라서 JSON에 타입 정보가 정확히 포함되어 있어야만 역직렬화가 성공할 수 있습니다.
앞서 분석한 GenericJackson2JsonRedisSerializer 내부 구조를 다시 살펴보면 다음과 같습니다.
- 직렬화: ObjectMapper의 writeValueAsBytes()를 그대로 사용
- 역직렬화: resolveType()으로 JSON 내부의 타입 정보를 확인하여 추론
즉, 직렬화 시점에 ObjectMapper가 타입 정보를 포함시키기만 하면, 역직렬화는 해당 정보를 기반으로 정상 동작합니다.
결국 핵심은 record에도 타입 정보를 강제로 추가하는 것입니다.
최종 해결책 – Record 전용 TypeResolver 구현
그렇다면 어떻게 record에 타입 정보를 추가할 수 있을까요? 앞서 분석한 GenericJackson2JsonRedisSerializer의 동작 방식을 통해, 타입 정보 생성 로직을 커스터마이징하는 것이 해결책임을 확인했습니다.
Jackson의 ObjectMapper의 내부 로직을 살펴보니 타입 정보 추가 여부를 결정하는 핵심 메서드는 다음과 같습니다.
public boolean useForType(JavaType t) {
if (t.isPrimitive()) {
return false;
}
switch (_appliesFor) {
case NON_FINAL:
while (t.isArrayType()) {
t = t.getContentType();
}
while (t.isReferenceType()) {
t = t.getReferencedType();
}
return !t.isFinal() && !TreeNode.class.isAssignableFrom(t.getRawClass());
case EVERYTHING:
return true;
// ... 생략
}
}이 메서드가 true를 반환하는 타입에만 타입 정보가 추가됩니다.
하지만 record는 자동으로 final 클래스가 되므로 !t.isFinal() 조건에서 걸러져 타입 정보가 누락됩니다.
이 코드에서 볼 수 있듯이, record일 경우에 타입 정보를 추가할 수 있도록 분기 처리를 하면 문제가 해결됩니다.
구현 방법: record 예외 처리 추가
기존 로직은 유지하면서 record에 대해서만 예외 처리를 추가하는 방식으로 해결했습니다.
public class RecordSupportingTypeResolver extends DefaultTypeResolverBuilder {
public RecordSupportingTypeResolver(DefaultTyping t, PolymorphicTypeValidator ptv) {
super(t, ptv);
}
@Override
public boolean useForType(JavaType t) {
boolean isRecord = t.getRawClass().isRecord();
boolean superResult = super.useForType(t);
if (isRecord) {
return true;
}
return superResult;
}
}위와 같이 useForType을 override하여 기존 레코드일 경우 타입 정보를 추가하도록 처리했습니다.
커스텀 TypeResolver를 ObjectMapper에 적용하는 방법은 다음과 같습니다.
RecordSupportingTypeResolver typeResolver = new RecordSupportingTypeResolver(DefaultTyping.NON_FINAL, mapper.getPolymorphicTypeValidator());
StdTypeResolverBuilder initializedResolver = typeResolver.init(JsonTypeInfo.Id.CLASS, null);
initializedResolver = initializedResolver.inclusion(JsonTypeInfo.As.PROPERTY);
mapper.setDefaultTyping(initializedResolver);이제 record 객체도 다른 클래스들과 동일하게 타입 정보가 자동으로 포함되어, 캐시에서 안전하게 역직렬화됩니다.
테스트 및 커뮤니티 확인
설정을 적용한 후 여러 케이스에 대해 테스트를 수행했고,
모두 직렬화 및 역직렬화가 정상적으로 동작하는 것을 확인했습니다.
@Cacheable(cacheNames = "user", key = "#id", cacheManager = "cacheManager")
public UserRecord getUser(Long id) {
return new UserRecord(id, "value");
}@SpringBootTest
class UserServiceTest {
@Autowired
private UserService userService;
@Test
@DisplayName("record에 class 타입 정보 포함하도록 커스텀 설정 후 테스트")
void getUser() {
Long id = 1L;
var notCachedTestRecord = userService.getUser(id);
UserRecord cachedUserRecord = userService.getUser(id);
assertThat(notCachedTestRecord).isEqualTo(cachedUserRecord);
}
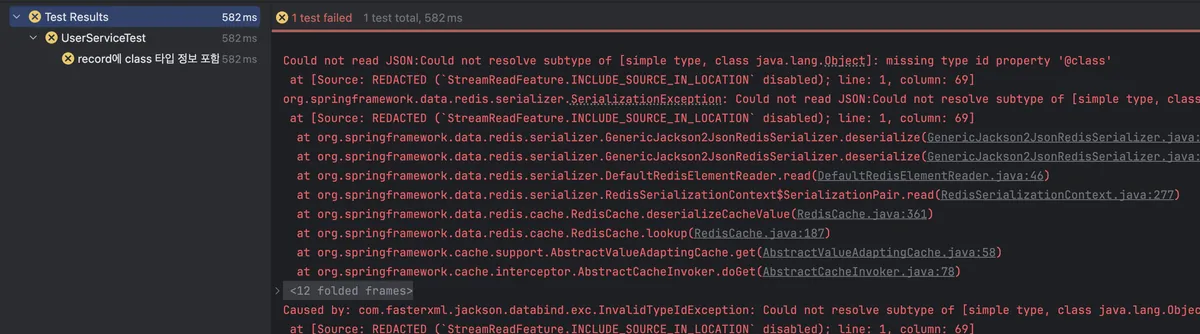
}RecordSupportingTypeResolver 추가하기 전 테스트 결과
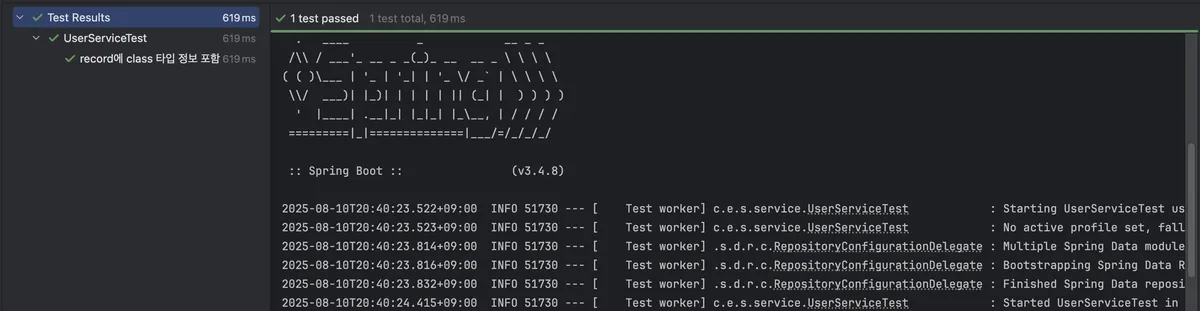
RecordSupportingTypeResolver 추가한 후 테스트 결과
또한 혹시 모를 예외 케이스나 부작용을 방지하기 위해, FasterXML 공식 이슈에서 컨트리뷰터와 논의한 결과, 해당 방식에 대해 긍정적인 반응을 받았고, 여러 테스트를 거쳐 큰 문제가 없을 것으로 판단했습니다.
이 방식의 장점과 주의 사항
- record의 장점을 그대로 유지할 수 있습니다.
- 자동으로 타입 정보가 붙어 직렬화/역직렬화가 동작합니다.
- Wrapper 클래스나 @JsonTypeInfo 누락 등으로 인한 실수나 장애 가능성 최소화할 수 있습니다.
주의 사항
직렬화 방식이 변경되면 기존 캐시 데이터와 호환되지 않아 역직렬화 오류가 발생할 수 있습니다.
배포 전 테스트 환경에서 충분히 검증하고, 필요시 cacheName에 버전을 부여해 기존 데이터와 충돌을 방지하는 것이 좋습니다.
마무리하며
이번 이슈는 단순히 “record는 직렬화가 안 된다”는 말로 넘기기에는, 그 이면에는 꽤 복잡한 구조적 배경과 라이브러리 간의 설계 의도가 얽혀 있었습니다.
Jackson은 다형성 처리를 중심으로 설계된 라이브러리고,
Spring Data Redis는 그 위에 캐싱 기능을 구축한 구조입니다.
결국 두 라이브러리 간의 관심사 분리의 미묘한 간극을 사용자인 우리가 직접 조율해야만 했습니다.
라이브러리는 분명 강력한 도구이지만, 때로는 그 내부 동작을 제대로 이해해야 진짜 문제를 해결할 수 있다는 것을 다시 한번 체감했습니다.
이 글이 같은 문제를 마주한 다른 개발자분들께 작은 힌트나 실마리가 되었으면 합니다.